MySQL常见问题
中文编码问题
client <-> server <-> 数据库文件
出现乱码的原因:
- Server 端使用的字符集
- client 客户端使用的字符集 (传递给客户端)
- database / table 使用的字符集
只要上面3个部分有一个使用了不支持中文的字符集就会出现乱码,注意这里并需要3个部位的编码都同时相同,因为它会自动进行转码,但是如果出现了不支持中文的字符集,那么就会转码失败,从而出现乱码问题。
比如;下面的显示结果中Server端的编码是指支持西欧语言的 latin1 字符集,当其与中文转码是就会失败,从而出现乱码。
查看编码:
SHOW VARIABLES LIKE 'character%';
输出结果:
VARIABLE_NAME | VARIABLE_VALUE
-------------------------+---------------------------------
character_set_client | utf8
character_set_connection | utf8
character_set_database | utf8
character_set_filesystem | binary
character_set_results | utf8
character_set_server | latin1
character_set_system | utf8
character_sets_dir | /usr/local/mysql/share/charsets/
| VARIABLE_NAME | VARIABLE_VALUE | 描述 |
|---|---|---|
| character_set_client | utf8 | 客户端编码设置 |
| character_set_connection | utf8 | 客户端与服务器连接编码设置 |
| character_set_database | utf8 | 当前所在的数据库字符集。如果在创建创建数据库时没有明确指定,则它和 character_set_server 一致(居然不和character_set_database相同)。 |
| character_set_filesystem | binary | 把os上文件名转化成此字符集,即把 character_set_client转换character_set_filesystem,默认binary是不做任何转换的 |
| character_set_results | utf8 | 响应给客户端数据的编码设置 |
| character_set_server | utf8 | 服务器端编码设置 |
| character_set_system | utf8 | character_set_system是个只读数据不能更改。 |
这里建议服务器端和数据库中都使用 utf8,当然其它支持中文的字符集也行,但utf8对各种语言支持的更好。
设置服务器端编码:
更改 my.cnf文件。在该文件的 [mysqld]下的character_set_server=latin1 改为 utf8。
更改database数据库的编码:
对于数据库 ,我们可以在创建数据库时就为其指定默认的编码:
|
|
也可以尝试更改现有数据库的编码:
|
|
也可对表进行上面的操作
设置连接客户端时使用的编码:
character_set_client、character_set_connection、character_set_results这3个参数值是由客户端每次连接进来设置的,和服务器端没关系,但是可以在服务器端的配置文件(my.cnf)中设置默认值。
在客户端执行下面的语句,为当前会话同时更改上面的三个值:
|
|
但是这样设置的值是临时的;可以在服务器的配置文件中为客户端设置默认值。
在服务器端为客户端设置默认值,更改配置文件中的 [mysql]下的default-character_set为utf8。
如果客户端是 cmd ,我们也可以将于客户端相关的值设置为GBK编码,配置方式与配置成 utf8 一致。
注意:客户端编辑器的字符编码问题不在该范围,比如服务器传递给客户端编辑器的编码与编辑器的编码不一致导致编辑器自身显示乱码,编辑器使用的字体不支持中文显示导致的乱码问题。
If you are using
cmd, typechcp 65001before using pandoc, to set the encoding to UTF-8.
大小写敏感问题:
常用的MySQL命令
这里指在系统终端或MySQL monitor中使用的命令。
在命令行中登录MySQL数据库的正确方式: 输入如下命令然后回车,接着会提示你输入密码(密码不可见)
|
|
(Linux中)开启/关闭MySQL服务:
|
|
MySQL的帮助命令:
|
|
参考: MySQL必知必会知识点总结一二
MySQL常用SQL语句
|
|
MySQL常用函数
字符串函数
-
LEFT(str,len) 返回从字符串str 开始,返回最左边起的 len 个字符。
1left(str,index),从index处开始截取str -
RIGHT(str,len) 从字符串str 开始,返回最右边起的 len 个字符。
1 2mysql> select right('foobarbar',4); -> 'rbar' -
LENGTH(str) 返回值为,字符串 str 的长度,测量单位为字节。一个多字节字符算作多字节。
-
CHAR_LENGTH(str) 返回值为,字符串 str 的长度,测量的单位为字符。一个多字节字符算作一个单字符。对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。
-
CONCAT(str1,str2,…)
返回结果为,连接 str1 和 str2 后产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。或许有一个或多个参数。 如果所有参数均为非二进制字符串,则结果为非二进制字符串。 -
INSERT(str,pos,len,newstr)
返回一个字符串 ,pos 表示要插入的位置,len 表示str中要被newstr覆盖的字符数(newstr会全部插入)。 如果pos 超过字符串长度,则返回值为原始字符串。若任何一个参数为 null,则返回值为NULL。 -
INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。这和LOCATE()的双参数形式相同,除非参数的顺序被颠倒。如若substr 不在str中,则返回值为0。
-
LOCATE(substr,str) , LOCATE(substr,str,pos) 第一个语法返回字符串 str中子字符串substr的第一个出现位置。第二个语法返回字符串 str中子字符串substr的第一个出现位置, pos 表示判断的起始位置。如若substr 不在str中,则返回值为0。
-
LOWER(str) 返回值是字符串。以及所有根据最新的字符集映射表变为小写字母的字符 (默认为 cp1252 Latin1)。
-
UPPER(str) 返回值是字符串。 以及根据最新字符集映射转化为大写字母的字符 (默认为cp1252 Latin1).
-
REPLACE(str,from_str,to_str) 返回值是字符串。这里 from_str表示str中的某个子字符串,to_str将会替换掉from_str。就是使用 to_str 替换 str 中的 from_str 这个子字符串。
-
REVERSE(str) 字符串反转
-
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
返回字符串 str , 其中所有 remstr (表示要被移除的字符串) 前缀和/或后缀都已被删除。若分类符BOTH (两侧)、LEADIN (左边) 或TRAILING (右边) 中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。
1 2 3 4 5 6 7 8SELECT TRIM(' bar '); -- -> 'bar' SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -- -> 'barxxx' SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -- -> 'bar' SELECT TRIM(TRAILING 'xyz' FROM 'xyzbarxyz'); -- -> 'xyzbar' -
RTRIM(str) 返回字符串,结尾空格字符被删去
-
SUBSTRING(str,pos)
-
SUBSTRING(str FROM pos)
-
SUBSTRING(str,pos,len)
-
SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 注意,如果对len使用的是一个小于1的值,则结果始终为空字符串。
-
SUBSTRING_INDEX(str,delim,count)
若count为正值,则返回从左边开始遇到的第count个定界符(delim)前所包含的内容。若count为负值,则返回从右边开始遇到的第count个定界符(delim)前所包含的内容。
1 2 3 4 5 6 7 8SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2); -- -> 'www.mysql' SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2); -- -> 'mysql.com' SELECT SUBSTRING_INDEX('www.mysql.com', '.', 1); -- -> 'www' SELECT SUBSTRING_INDEX('www.mysql.com', '.', -1); -- -> 'com'
字符串比较函数
还是把示例也抄下来
select 的另一个用法
日期函数
多表查询
笛卡儿积 (没关联条件)
|
|
内连接 (只查找有关联的数据)
|
|
外连接:
连续的两个左外连接:
|
|
测试语句1:
|
|
测试语句2:
|
|
使用到的表格:
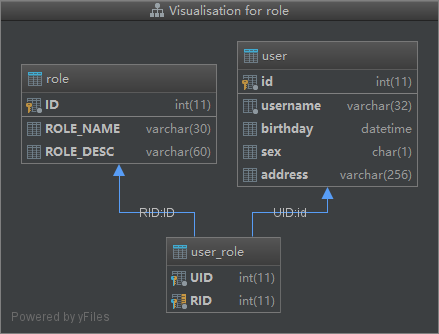
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34CREATE TABLE `user` ( `id` int(11) NOT NULL auto_increment, `username` varchar(32) NOT NULL COMMENT '用户名称', `birthday` datetime default NULL COMMENT '生日', `sex` char(1) default NULL COMMENT '性别', `address` varchar(256) default NULL COMMENT '地址', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `user`(`id`,`username`,`birthday`,`sex`,`address`) values (41,'老王','2018-02-27 17:47:08','男','北京'),(42,'小二王','2018-03-02 15:09:37','女','北京金燕龙'),(43,'小二王','2018-03-04 11:34:34','女','北京金燕龙'),(45,'传智播客','2018-03-04 12:04:06','男','北京金燕龙'),(46,'老王','2018-03-07 17:37:26','男','北京'),(48,'小马宝莉','2018-03-08 11:44:00','女','北京修正'); CREATE TABLE `role` ( `ID` int(11) NOT NULL COMMENT '编号', `ROLE_NAME` varchar(30) default NULL COMMENT '角色名称', `ROLE_DESC` varchar(60) default NULL COMMENT '角色描述', PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `role`(`ID`,`ROLE_NAME`,`ROLE_DESC`) values (1,'院长','管理整个学院'),(2,'总裁','管理整个公司'),(3,'校长','管理整个学校'); CREATE TABLE `user_role` ( `UID` int(11) NOT NULL COMMENT '用户编号', `RID` int(11) NOT NULL COMMENT '角色编号', PRIMARY KEY (`UID`, `RID`), KEY `FK_Reference_10` (`RID`), CONSTRAINT `FK_Reference_10` FOREIGN KEY (`RID`) REFERENCES `role` (`ID`), CONSTRAINT `FK_Reference_9` FOREIGN KEY (`UID`) REFERENCES `user` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `user_role`(`UID`,`RID`) values (41,1),(45,1),(41,2);
添加与修改表注释、字段注释
1 创建表的时候写注释
|
|
2 修改表的注释
|
|
3 修改字段的注释
|
|
4 查看表注释的方法
|
|
5 查看字段注释的方法
|
|
麦子学院:MySQL基础
|
|
麦子学院:MySQL进阶
|
|
数据备份与还原
|
|
序列
|
|
性能优化
执行计划
sql执行性能分析命令explain
用法示例:explain select * from test;
|
|
group by的相关问题
MySQL 5.7 之 默认ONLY_FULL_GROUP_BY语义介绍: https://blog.csdn.net/guyan0319/article/details/79282616 https://www.aliyun.com/jiaocheng/1107229.html
MySQL 5.7.5及更高版本实现对函数依赖的检测。如果ONLY_FULL_GROUP_BY启用了 SQL模式(默认情况下),MySQL会拒绝那些select列表,HAVING条件或 ORDER BY列表所引用的查询,这些查询既不是在GROUP BY子句中命名的,也不是在功能上依赖于它们的非聚合列。(在5.7.5之前,MySQL没有检测到函数依赖,并且 ONLY_FULL_GROUP_BY默认情况下是不启用的。
而对于语义限制都比较严谨的多家数据库,如SQLServer、Oracle、PostgreSql都不支持select target list中出现语义不明确的列,这样的语句在这些数据库中是会被报错的,所以从MySQL 5.7版本开始修正了这个语义,就是我们所说的ONLY_FULL_GROUP_BY语义,例如查看MySQL 5.7默认的sql_mode如下
MySQL 5.7 之 默认ONLY_FULL_GROUP_BY语义介绍 - CSDN博客
mysql5.5迁移到5.7默认选项ONLY_FULL_GROUP_BY引发的问题 - 阿里云
MySQL5.7 group by新特性,报错1055 - CSDN博客 这里说了如何取消该特性。
